写于二十年前(2003年)的文章,现在依然受用。
你是否曾探究过HTTP请求中神秘的Content-Type?你是否曾遇到过满是问号 ???? ???? ?? 的电子邮件(或网页)?
作者发现多数程序开发人员并不是完全明白字符集character set、编码encoding、Unicode、UTF-8等相关话题。
这篇文章回顾了字符集的发展历史。
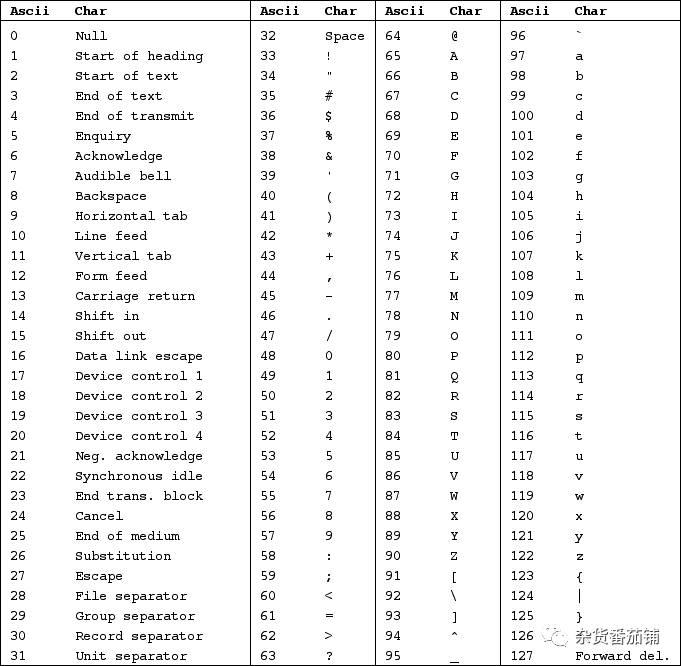
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)
回到Unix正在被发明的上古时代,一个英文字符的ASCII值可以用 32-127 范围内的数字来表示,包括英文字母、数字和符号。
比如空格是32,A是65,a是97。 0-31 被用作操作符。如10为换行,13为回车。
计算机的最小寻址单位是一字节(8个比特),127只需要7个比特位就能表示(2的7次方=128),所以还有一比特位(值128-255)空闲。
这些空闲的值在不同的语言地区被赋予不同的用法。比如美洲地区用130来表示é,但是以色列的电脑用130来表示希伯来字符ג。那么在美洲电脑上显示的单词résumés,在以色列的电脑上就成了 rגsumגs。这导致了同一文档内容在不同的电脑上可能有不同的显示。
Code Page(代码页)
ANSI(American National Standards Institute,美国国家标准学会)在制定标准的时候,引入了代码页。
这些代码页128以下是一样的,只有128以上不同。如,以色列使用code page 862,希腊使用 code page 737。
这样在同一电脑上可以有多个不同的代码页可供选择。
DBCS(Double Byte Character Set,双字节字符集)
但是,由于亚洲语言有成千上万的字符,没办法用一字节(8比特)完全表示。
DBCS 是对英文字符使用单字节,其他字符(如中日韩文)使用双字节。访问文本时,只能从前向后处理。因为需要一直判断当前字节是不是前导字节,对于既有可能是前导也有可能是后续的字节,只能通过上下文做判断。
对计算机程序及程序员来说,操作起来比较麻烦、容易出错。
Unicode(统一码、万国码)
一套可以适用于全世界所有国家的字符集。
对 Unicode 最常见的误解是:每个字符占用16比特,因此能表示的字符个数是 2的16次方=65536个。实际上,这是不对的。
Unicode 中对所有字母表中的每个字符分配一个数字——code point,如 A 的code point 是 U+0041;迪的 code point 是 U+8FEA。
Unicode 中的字符,是一个概念定义。比如字符A,很明显A不同于B,也不同于a,但是无论是斜体的A、粗体的A、还是正常的A,它们应该是一样的,都是字符A。对于字体Times New Roman中的A,应该和字体Helvetica中的A一样,都是字符A。(对于字符A,Unicode只定义U+0041是字符A,而具体的这个字符显示出来时什么样子,是定义在字体文件中的)
UCS-2 / UTF-16
那么 He 用 Unicode 表示就是 00 48 00 65。
对吗?憋着急。那它为啥不能是 48 00 65 00 呢?技术上来说没有问题,而实际上也是两种方式都存在(因为特定的 CPU 用特定的顺序会更快)——大端序(big-edian)和 小端序(little-endian)。
为了区分,在文本开头加上字节顺序标记位,大端序用 FE FF,小端序用 FF FE。
这种方式对于新生成的文档没有任何问题,但是无法兼容已有的ASCII和DBCS文档。
UTF-8(Unicode Transformation Format 8-bit)
所以,出现了另一种实现 Unicode 字符集的系统——UTF-8。它采用变长的编码,用一个字节存储 code point 0-127,对 128 以上的使用 2字节、3字节,最多到 6字节。
比如,表示字符 ₤ 的 Unicode 十六进制值为 U+20A4,其二进制为 0010 0000 1010 0100。用UTF-8 来表示字符₤的话,需要3个字节:
- 第一个字节的前四位,用
3比特1(代表3个字节)加一个0:1110。后四位接20A4的前四子节:0010。得到1110 0010。 - 第二子节以
10开头,后六字节接20A4的六字节0000 10,得到1000 0010。 - 第三子节还是以
10开头,后六字节接20A4最后六字节10 0100,得到1010 0100。
最终得到字符₤的UTF-8表示为1110-0010 1000-0010 1010-0100。
对于英文文档来说,
UTF-8和ASCII是一样的,不需要任何转换。
UTF-8 比 UTF-16 省空间吗?
不一定。
| 字符串 | UTF-8 | UTF-16 | 空间比较 |
|---|---|---|---|
AI |
4149 |
0041 0049 |
UTF-8<UTF-16 |
射雕 |
E5B0 84E9 9B95 |
5C04 96D5 |
UTF-8>UTF-16 |
如果存储数据英文字符较多,
UTF-8肯定会比UTF-16节省空间。
Encodings(编码)
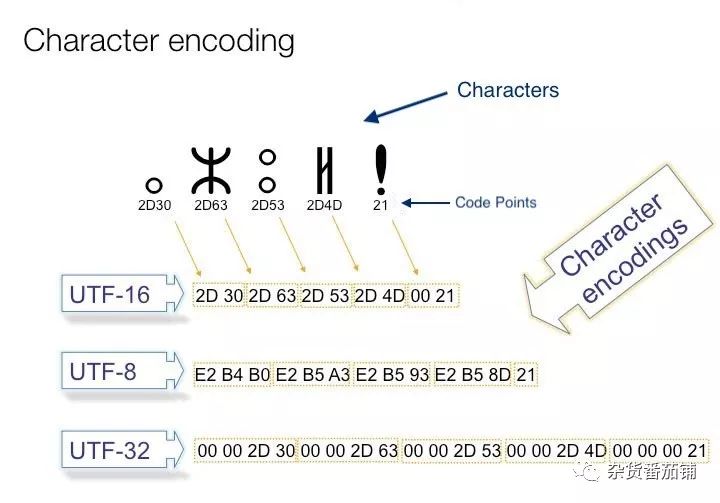
Unicode是字符集,上面说的 UCS-2、UTF-8等是实现Unicode的方法——Encoding。Encoding有多种实现,如UTF-7、UTF-32、ISO8859-1。
所以,必须确定所用的Encoding才能正确处理一个字符串。
在浏览器中看到这每个网页会有Encoding的信息:
|
|
可是,在不知道encoding的情况下怎么去读这个HTML文件来取到encoding的信息呢?
幸运的是,绝大多数encoding对 32-127 的code point的处理方式是一样的,可以把文件开头的内容当作ASCII来处理。所以encoding信息越早出现越好,避免出现在任何code point大于127的字符之后。
另外,HTTP请求头中也可以包含encoding信息(Content-Type)。
早期的浏览器都有设置encoding的菜单,以应对找不到encoding定义而无法正确处理的情况。大部分现代浏览器(如Chrome)已经去掉该菜单,可以根据上下文判断出正确encoding了。
原文链接
- The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!)
- 每个程序员都应该知道的字符集发展简史